rabbitmq
http
桥接模式
人脸识别
labview
MCAL
两数之和
博通蓝牙使能
OData
科研绘图
openresty
机顶盒ROM
cannonjs
手机浏览器下载视频
数据治理
Material Design
鹈鹕优化算法(POA)
读书
acquireQueued
opengl
单机多卡
2024/4/13 1:05:59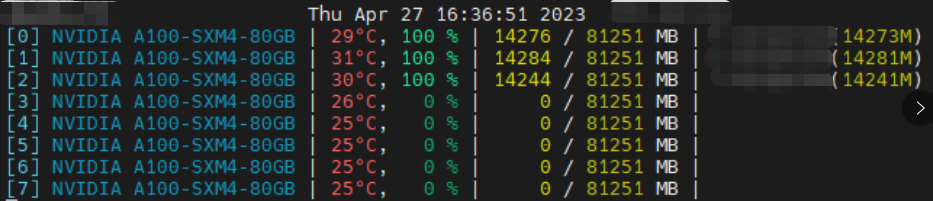
A100单机多卡大模型训练踩坑记录(CUDA环境、多GPU卡住且显存100%)
踩坑1:服务器只装了 CUDA Driver 没装 CUDA Toolkit
系统:Ubuntu-18.04 用 deepspeed 跑百亿模型训练时,报关于 CUDA_HOME 的错误。
AssertionError: CUDA_HOME does not exist, unable to compile CUDA op(s)执行 echo $CUDA_HOME 和 nvcc…

【计算系统】分布式训练:DDP单机多卡并行实战
分布式训练:DDP单机多卡并行 1. 分布式训练总览1.1 并行方式1.2 PyTorch中数据并行方法1.3 训练原理1. DataParallel(DP)训练原理2. DistributedDataParallel(DDP)多卡训练的原理 2. PyTorch分布式代码实战2.1 不使用DDP和混合精度加速的代码2.2 使用DDP对代码改造后…

使用huggingface的accelerate库出现张量不在同一个设备的RuntimeError
报错如下 RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:2! 原因分析
模型的层数过多时,可能有些层被分到了不同的GPU上
解决方案
首先打印看看自己的模型有哪些模块,比如WizardCo…

使用hugging face开源库accelerate进行多GPU训练(单机多卡)时,在保存模型结构的时候出现的问题
目录 问题描述问题分析问题解决 问题描述
我在保存模型结构的时候,先获取模型参数,然后再保存,代码如下: 图示代码是在训练主循环中的:
这种情况下会出现报错:
nboundLocalError: UnboundLocalErrorloc…